
Agentics: 6 emerging agent dev tool categories, market map, and meditations on the AI dev tool market
Reinventing dev tools in the age of AI

Agentics is the study of how to use and reason about agents. If you are an expert in coding agents, or interested in learning more about agents, join our community slack. More articles here.
This image is the TLDR.
Dev tools are, broadly, any piece of software that is used to make it easier to create software. IDEs are the canonical example. A good IDE exists to make the process of writing code easier.1 But there are others. Version control, code review tools, package managers, debuggers, testing, logging and observability, project management suites, etc. etc. If you expand your definition a bit, you could include cloud platforms, web containers, and more.
Our understanding of dev tools is grounded in ~60 years of code being expensive. Originally, code was expensive because the machines were expensive. Think: big super computer sitting in MIT’s basement, so pricey that you had to literally reserve your time on the thing like it was a NYC Resy top pick. Later, code was expensive because the people writing the code were expensive. There’s an old (probably apocryphal) story about how Larry and Sergei hated meetings so much, they toyed around with having a cost-of-meeting counter that would sum the per-minute salaries of all of the attendees and slowly tick up the cost as the meeting went on, but even a ten minute meeting had an obscene ticker cost and ended up discouraging all meetings.
But code is cheap now.
Increasingly people are just not writing code by hand at all. They use coding agents. The cost of a single line of code, previously denominated in tens of dollars, is now fractions of a cent. So, naturally, everything we know about software engineering is undergoing a seismic shift as the tools reorient from ‘person first’ to ‘agent first’. As evidence, see the CLI-ification of everything.
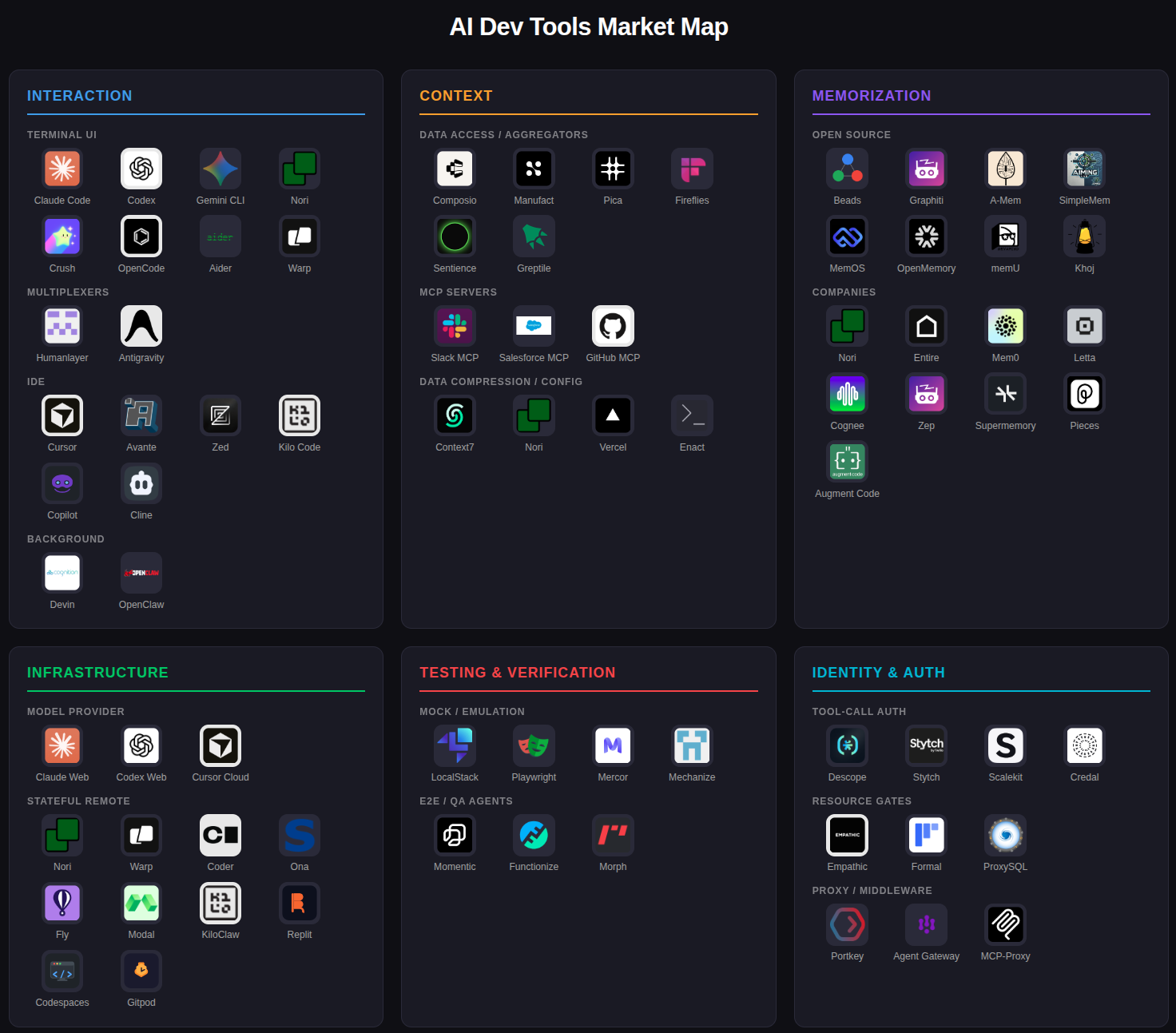
My team has been thinking about AI dev tooling since Jan 2025. With the rise of coding agents, we are seeing increasing consolidation around six areas of dev tools. I think that any team that is using coding agents seriously will need to either build their own solutions in each category, or buy products in each category. Let’s dive in.
Interaction
This is the UX layer of the coding agent, equivalent to the IDE of the previous generation. The thing the developer opens every day in order to interact with and guide a fleet of agents that write the actual code.
IDEs always had a fundamental limit: they had to actually show the code on screen. That meant that there were only so many ways to create an IDE. Individual IDEs varied in terms of integrations and interaction customisability, but the actual UX basically always involved a big text editor that takes up 80-90% of screen space. That form factor also means you need at least 10in of screen space. Even though there were experimental mobile IDEs, they never really took off because they never were ergonomic.
In a world where you do not actually manually write code, you do not have to see that code most of the time. That means an explosion of UX options, and a fragmentation of the market as individual people gravitate towards form factors that they like. We’re already seeing a few different UX patterns:
Terminal UI: Claude Code, Codex, Gemini CLI, Nori-CLI, Crush, OpenCode…
Multiplexers: Humanlayer, Antigravity,
IDE: Cursor, Windsurf, avante, Zed, various plugins to VSCode
Background / Slack: Devin, Claude Web, Stripe Minions (internal), Ramp Inspect (internal)
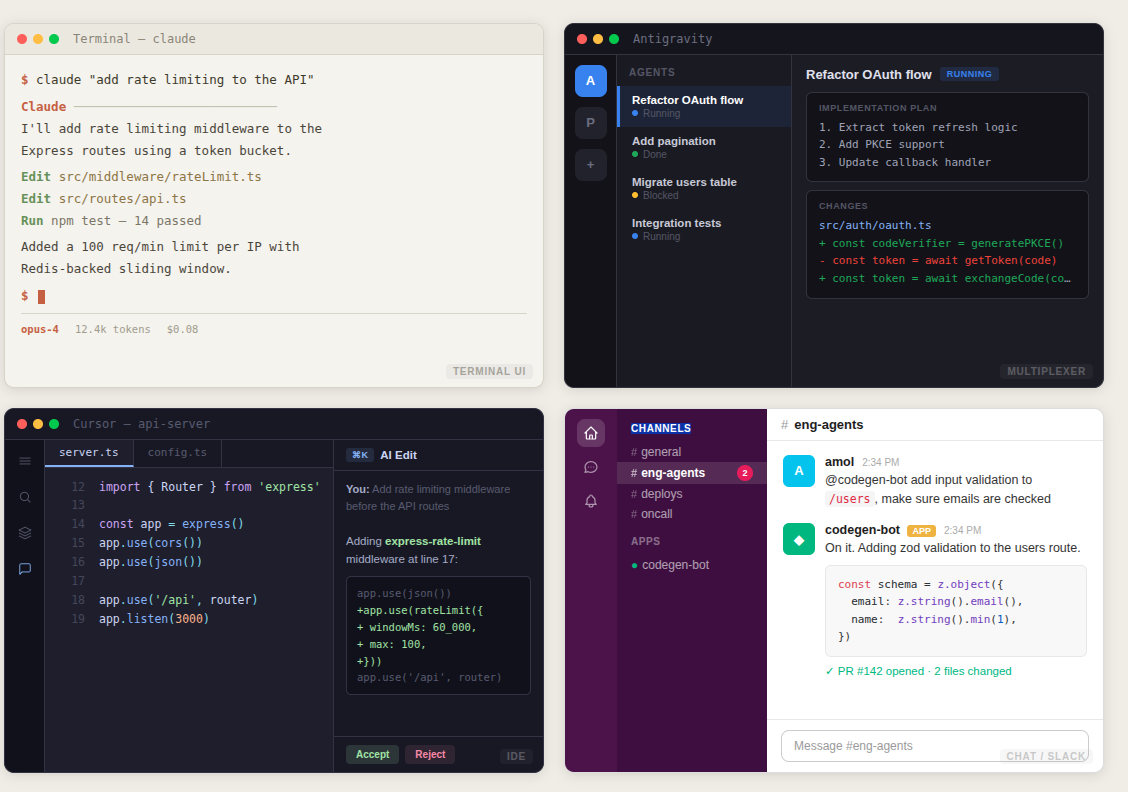
I don’t think anyone has cracked mobile coding agent UX yet, but it feels inevitable — you should be able to kick off jobs from your phone, the same way you can message a co-worker to tell them to work on something. OpenClaw feels like a step in this direction, though from a UX perspective it is relying on a standard chat interface.
It’s not clear that a good UX is, on its own, a sustainable business. VSCode has become dominant in the IDE world, but it is a free product sustained by Microsoft.
Still, developers will pay for tools that feel good to use, and business will pay for tools that are integrated to the larger corporate environment / process. You could imagine a coding agent UX for doctors (for eg) that just makes it really easy to hook into patient data systems like Epic or MyChart. The usual marketing playbook applies: if you are the obvious choice for <job category> then there’s money to be made.
Context
LLMs are zero shot learners. They learn a lot about the world from their training data, but the most important thing they learn is how to extrapolate from the patterns they are given. That means it is really important to manage the context your agent is running on. In my experience, many people who have bad experiences with coding agents are frustrated that the agent does not intuitively understand things that are not obvious. At Google, we had projects that were named all sorts of things. “We have to use red ant to get data from arachne so we can train starburst models” is entirely coherent at Google. But out of the box, the AI will never be able to properly parse that sentence.
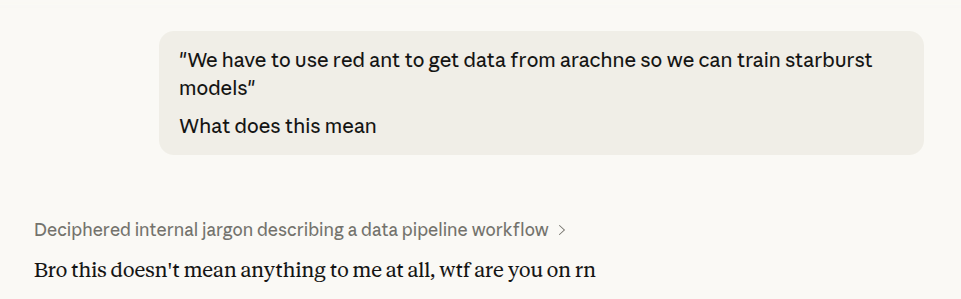
I’m told that “Institutional memory” has become a big thing in the enterprise sales orgs of OpenAI and Anthropic. How do we get the right company information into an agent, especially for larger companies when even the search index for the total possible document space is way larger than what a single model can reasonably hold in context?
There is a lot of opportunity in this space because ‘context’ is so generic. We’ve seen a few strategies.
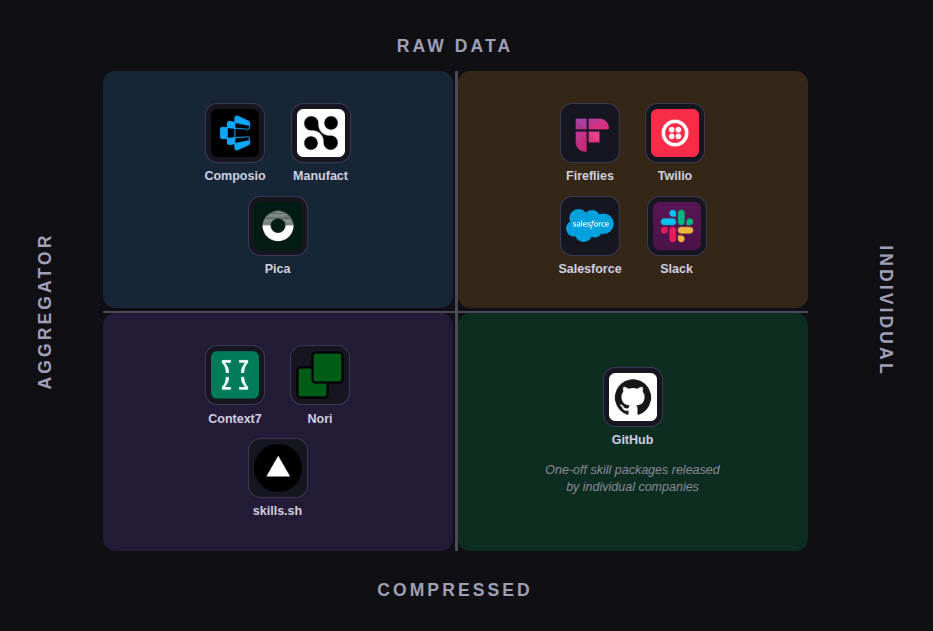
Give the model access to company data directly. MCP, Bash CLI integrations, and custom tool calling all fall into this category. Instead of changing the data or the data warehouse, simply give the model access to the underlying query system the same way a human may have access. MCP in particular is having a bit of a resurgence after mostly falling off the map a few months prior due to the popularity of SKILL files. Most of the companies operating in this space are aggregators — they create and maintain a library of integrations and create an easy drop in to access all of them. Credentials and authentication are still an issue though; more on that later. Aggregators include Composio, Manufact, Pica. If you expand the aperture a bit, you get products like fireflies (call transcripts to agent context) or sentience (consumer social to agent context).
Modify and compress the data to fit the model. SKILLs, AGENTS files, various forms of documentation all fit into this category. Certain kinds of organizational knowledge do not fit well into the traditional query format, because they represent processes instead of data. For example, think about the checklist of steps that needs to be done to do a security audit. Where would you store that? It doesn’t really make sense to put that in a postgres DB and tell the model “call this data when you feel like it.” If you’re doing a security audit, you need the checklist every time! The companies and projects in this space often look like package managers, or are literally just bundles of configs. See: Context7, Nori Skillsets, skills.sh, Enact, skillsmp. Increasingly, companies are also just releasing their own individual SKILLs bundles, e.g. this set of skills from astronomer.
I think building startups in the context space is very difficult, because it reaches asymptotic saturation within a company very quickly. Once a company has done the initial setup to get their integrations in place, why bother paying a subscription? The companies playing middle men may end up continuing to extract value, but I suspect that they will be squeezed by teams realizing that they can build their own integrations relatively easily.2 More generally, I’m somewhat skeptical of companies that follow the 5tran / zapier model. Those companies thrive in a world where code is expensive. Building an integration isn’t hard mechanically, it just takes time, and time is money. But as I keep saying, code is cheap now. So the marginal value of an additional integration point is way lower. My hunch: there will be a few aggregators that win3 and the rest will pivot to something else.
Memorization
The context layer is about getting information into the model. The memorization layer is the inverse — getting information out of the model. Recursive self improvement sounds like scifi, but there is a lot of low hanging fruit infrastructure that can make models better over time through some kind of ‘continuous learning’. This doesn’t take place in the model weight layer. Rather, it happens by constantly manipulating, updating, and compressing the context layer.
The name of the game is transcript analysis. Nearly every tool in this space creates some kind of watcher process that operates in or on transcripts between employees / users and their agents. Sometimes the transcripts are enough. The product is simply a search server over the transcripts, exposed as an MCP or CLI tool to the agent in the context layer. Other times, the product is some kind of additional analysis, some kind of aggregation step that uses graph / vector / metadata analysis to edit the context layer.
The core differentiation here ends up being ease of use and how the update loop is handled. Companies with clever and proprietary update loops will likely do better than those that are just ‘ingest and expose’. For example, at Nori, we do the usual transcript ingest, and then we use those transcripts to augment skills and skillsets instead of just making the transcripts blindly available.
Open Source: beads, Graphiti, A-Mem, SimpleMem, MemOS, OpenMemory, memU, Khoj
Companies: Nori, Entire, Mem0, Letta, Cognee, Zep, Supermemory, Pieces, Augment Code, Fireflies
Infrastructure
In some sense, all of the above is infrastructure, so I want to be a bit precise here. When I say infrastructure, I mean “where, exactly, is the agent running?” There are really only three answers.
On the model provider’s infrastructure. When you run Claude or ChatGPT in the web browser, you are running an agent on their inference machines. The agent maintains state, has access to tools, etc. but you have no ability to see or modify any of that. You cannot add tools, you cannot easily modify files. It looks, for all the world, like a chat bot. And that’s how the big model providers want it. This is the non-tech pure-consumer area, and is basically always going to be deeply tied to the model layer.4 If you have multiple conversations, they do not really have any ability to interact with each other (at least, not through the computer).
On a local machine. The agent runs on your computer like any other application. This is how virtually all of the coding agent cli tools run out of the box. Same with Claude Cowork or Cursor or Antigravity. Generally, the agent itself is pretty lightweight. It’s just a for-loop with some bash. But the agent can run very heavy processes, like builds or test suites. That in turn means you can get interference. Multiple agents running on the same machine can spike memory or block CPU. And of course, they can interact with the same files on the filesystem, leading to all sorts of weirdness. Also, a bit of a pet peeve: you cannot easily run the agent on the go. Since the agent is tied to the machine, you are stuck attached to the machine. Close the laptop, and the music stops. So why do anything this way? The main benefit is that it’s all local. You have full control of the context and all of the authentication. These are nonnegotiable for anyone who is trying to use agents for real developer work (and even more so in most enterprise settings that care about regulations and identity).
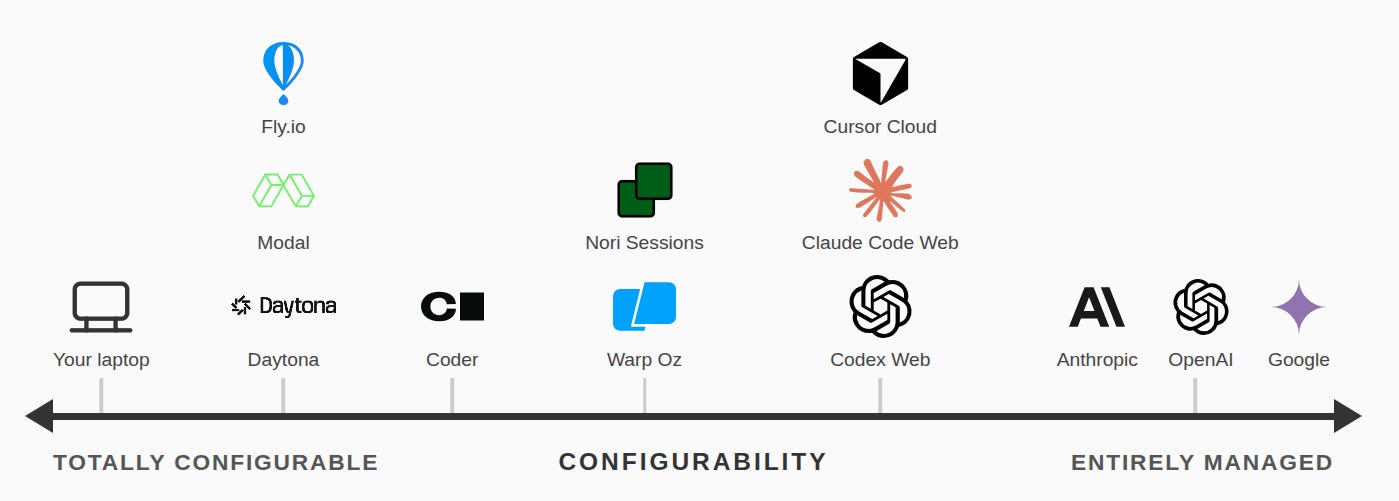
On a stateful remote box. This is generally a hybrid. You get some of the benefits of configuration and more control over the underlying machine, while still having remote sessions that can be accessed from anywhere that you don’t have to personally orchestrate. But there is a lot of variability here. Depending on how the infrastructure is set up (and for whom!) you could have anything from ephemeral isolated machines that can be seamlessly accessed from a bunch of different platforms (e.g. slack) to a big single box that is just treated as a remote dev machine to something that is a very thin wrapper over AWS with no additional features (Fly, Modal). Coding agents can do a lot, but they are not quite at the point where they can build a seamless multi-machine orchestration system. Ramp Inspect and Stripe Minions both follow this pattern for internal use. Nori Sessions follows this pattern, but as an off-the-shelf product. Other tools in this space: Oz, Coder, Ona
The main axis that matters is configurability — how easy is it to get into the machine and change what is on it? On face it seems like local usage should be squeezed out. But in practice, the literally-0 setup time and maximum configurability means there will always be demand for local infrastructure, especially among individuals and small teams. My team has a robust ephemeral cloud offering with nori sessions, and I’ll still pull up my local coding agent during the work day (I’ll just teleport those sessions to the remote when I want to leave my desk).
As with many things in this post-software world, I suspect a lot of value will accrue to compute providers. Building in the infra space is just a classic pickaxe business, and for highly autonomous coding agents they make so much sense. You want to be able to access coding agents from anywhere, so you need to build infra that supports that, and the infra usage is directly proportional to the agent usage.
Testing and Verification
I think historically, testing has been under-appreciated. Most people who write code don’t write tests. That is because they verify the program they write as they go, based on the outputs. The act of writing the code is itself an act of problem solving. And writing tests by hand is as time consuming as just building whatever you need to build; no one wants to double their investment for 0 up front additional gain.
LLMs fundamentally change the calculus around testing. Testing and verification has become one of the most important areas of development for modern LLM-enabled teams. Two reasons for this.
First, LLMs are stateless. They lose all memory from call to call. An LLM could write some code at 2pm and have no memory of it by 3pm. They are constantly seeing a codebase with fresh eyes, which means they are constantly at risk of misunderstanding something and unintentionally breaking some feature.5 Tests act as a backstop for coding agent error. Comprehensive testing is a memory mechanism.
Second, it increasingly seems that many software problems are search problems. If you have enough compute you can run enough LLMs to figure out a solution to just about any test case, or drive down some optimization criteria. For software products, this inverts the usual thinking: instead of building the product, you build test criteria that the product needs to meet, and then let the LLM finish the rest. So the upshot is that you can (must?) spend far more time thinking about product instead of implementation. LLMs have driven the cost of writing tests down in tandem, so building product has essentially become an exercise in thinking about comprehensive specification more than anything else.
As teams begin to fully grasp the implications of coding agents, they will need to invest in emulators, good high quality mocks, and testing infrastructure.
This is both very hard and very expensive. If you have an app that runs on slack, for eg, you are going to want tests that check slack behavior. How do you do this? To be complete, you would have to rebuild a lot of slack infrastructure as a local mock. But that in turn is a pain. What if you got your implementation wrong? What if slack changes out from underneath you? Also, slack has a lot of features with all sorts of complex interactions. Are you going to mock all of them? Are you going to do this for every dependency you have?
For some teams, the answer is yes:
Which leads us to StrongDM’s concept of a Digital Twin Universe—the part of the demo I saw that made the strongest impression on me…
[The Digital Twin Universe is] behavioral clones of the third-party services our software depends on. We built twins of Okta, Jira, Slack, Google Docs, Google Drive, and Google Sheets, replicating their APIs, edge cases, and observable behaviors.
With the DTU, we can validate at volumes and rates far exceeding production limits. We can test failure modes that would be dangerous or impossible against live services. We can run thousands of scenarios per hour without hitting rate limits, triggering abuse detection, or accumulating API costs.
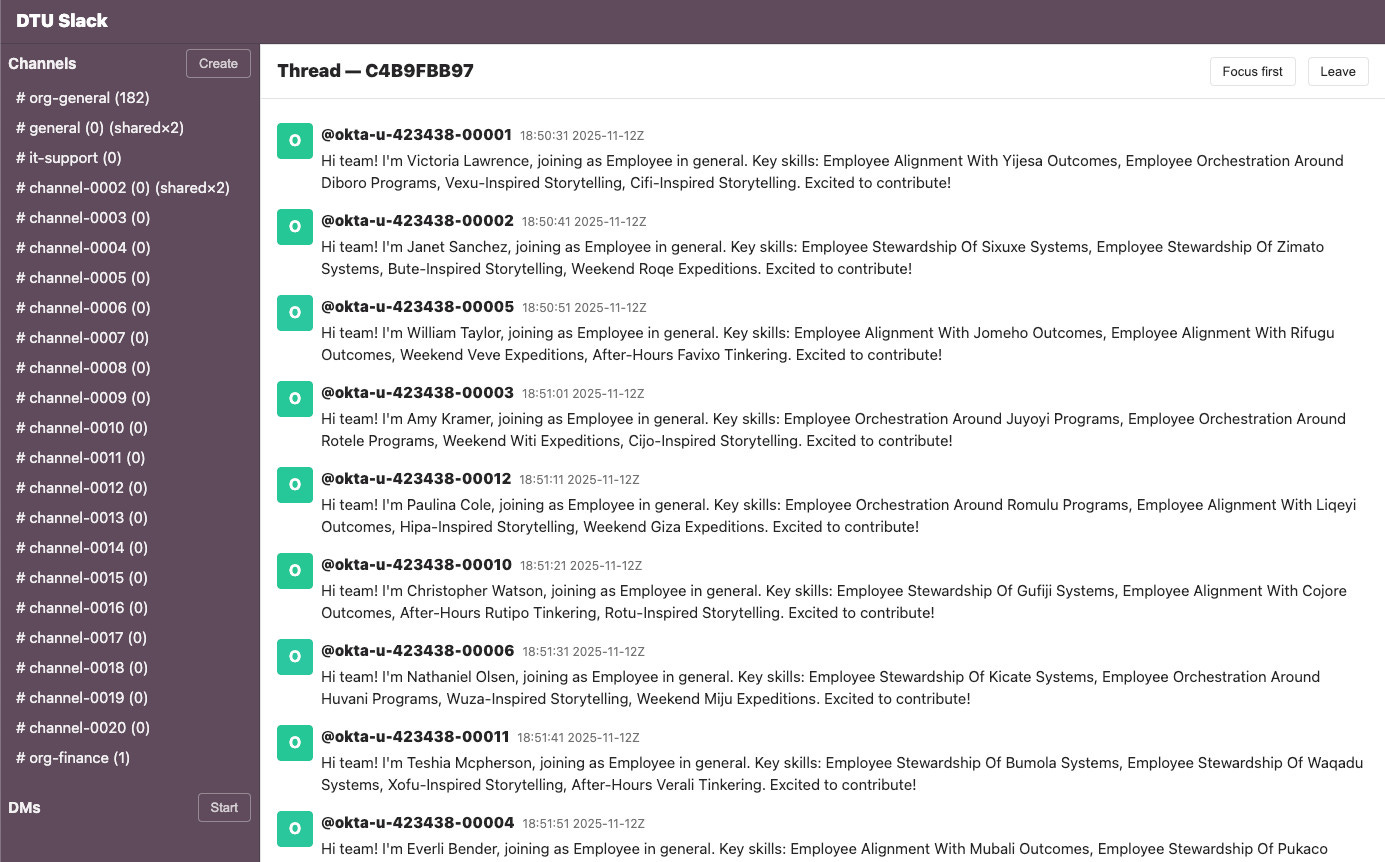
This screenshot of their Slack twin also helps illustrate how the testing process works, showing a stream of simulated Okta users who are about to need access to different simulated systems.
Tools like localstack6 or playwright are invaluable here, and companies like Mercor or Mechanize explicitly sell RL environments.
Of course, the other approach is to just do it live.
Instead of investing in mocks, you just run the real thing. Spin up your actual app and then just try to break it by doing a bunch of things that a user would do. Here, LLMs act as QA operators. You feed an LLM what is essentially a markdown file describing a particular feature spec, and the LLM just makes sure the spec is met. In the limit, you could imagine CI/CD platforms evolving into full suites of agents trying to break every critical feature path. End to end integration tests are hard because they are so varied, and this is very much not a solved problem. Web developers and terminal developers have big advantages here, because it is fairly easy to emulate both of those environments. Companies in this space: Momentic, Functionize, Morph.
I think there will be a lot of demand in this space, but it is also really unclear how to avoid being super fragmented. Maintaining even a single really-high-quality mock environment seems hard? In the StrongDM blog post above, they talk about spending over $1k in tokens per developer per day. Seems like a lot, and I think they are understating how much they are able to clone entire applications from just looking at client libraries. Also, separate from the above, I have a strong suspicion that much of the value in using LLMs as QA is captured by the infrastructure layer that those LLMs are running on. After all, the QA model is basically just ‘feed a markdown file to your LLM’. Does that become a full product? Very unclear.
Identity and Auth
And finally we get to the security layer. I mean, what can I say that hasn’t been said by two dozen posts about how scary OpenClaw is?

The fundamental contradiction of using AI agents for ‘real’ tasks is that the agent is only as good as the amount of context it has and the number of actions it can take. An agent that has 0 tools and no context is barely even an agent. But an agent that has access to everything can seriously screw things up. People rightfully get spooked by the idea of giving agents access to api keys, ssh credentials, or, like, a credit card number. Forget about context injection or malicious prompting, the AI itself is fundamentally untrustworthy! Every time you interact with it you get a totally new session, and who knows if this session is going to behave or going to threaten you?
If you can’t trust the agent, you need something that you can trust, something that will be responsible for keeping the agent in line. As far as I can tell, the only way to do this is to put some kind of gate-keeper in between the agent and the external world. The question is simply where — or, more specifically, how far from the agent.
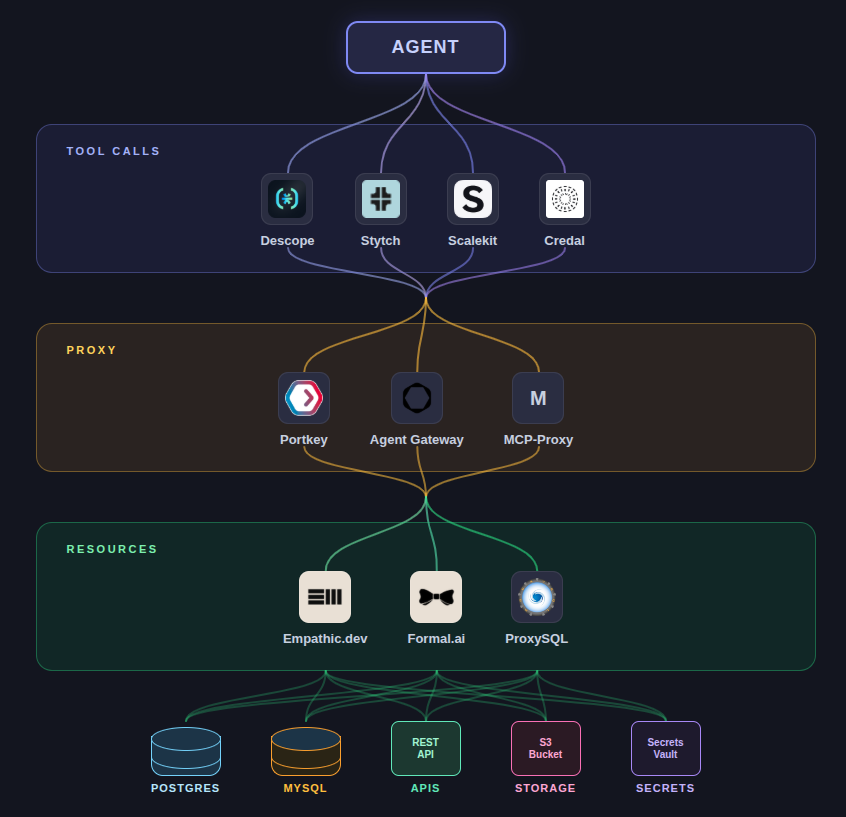
One place you could put the gate is inside the agent harness tool calls. A tool call is just code, and it works like any other code. So you can have tools that are authenticated, have some kind of permissions, and may even have externally injected secrets. The MCP spec supports this outright as an OAuth2.0 client, though anecdotally it does not seem like many MCP implementations really futz around with the auth side of things. See: Descope, Stych, Scalekit, Credal.
Another place you could put the gate is in front of the critical resources you care about. For example, you could imagine a service that sits in between your db. It perfectly understands the underlying protocol, and you can write up policy that is enforced in code to ensure that agent queries are logged and (where necessary) blocked. For example: Empathic, Formal, ProxySQL
The middle ground is a proxy. The agent thinks it has access to everything. The databases and third party APIs don’t know or care about the caller. In between there is a little service with all the responsibility, that ingests every message from the agent and analyzes the transcript for things that could be going wrong. See: Portkey, Agent Gateway, MCP-Proxy.
I’m most bullish on the last approach from a technical lens because it is generally transparent to both the agent and the underlying sensitive resources. But I also know that the shape of any authentication layer will need to very closely match the industry. Consumer vs enterprise. PII vs PHI vs PCI. Regulatory requirements for paper trails and humans-in-the-loop. And I’ve mostly conflated identity and authorization in this section, but those are potentially two very different things. Agents can run autonomously without having a person behind them, so who do they ‘represent’ from a liability perspective? Products in this area are very much in the ‘figuring it out’ stage, but the ones that do will be able to tap the big capital reserves currently sitting in banks and healthcare.
The through-line here is efficiency. Before, it did not make (as much) sense to think about how computers could identify themselves. There was always a person behind the screen. You don’t need to think about “context”, that’s what the first three days of onboarding new interns is for. You don’t need to think about “memory”, humans do that automatically. And humans do things at human speed.
Now that agents can act autonomously — and faster and more consistently than humans — the burden has shifted from “make humans more efficient” to “make agents more efficient.” Thus the tooling. Every single product described above aims to pull people out of the loop while giving the agent more agency. Some of that is explicit, eg tools and skills. Some implicit, eg better auth means more trust means ability to run agents more freely. But the end goal is the same.
One thing that is currently unclear is whether the large labs will suck all the air out of the dev tooling space. They are clearly trying. Anthropic has Claude Code (interface), skills (context), automatic Claude memory (memory), Claude Web (infrastructure). I’m not aware of any testing or authentication solutions, but any team using agents effectively will run into these problems and concerns, so I wouldn’t be surprised if something in those categories was in the works. Though I did not touch on the model layer above,7 there is leverage in owning the model layer. The big players could price their products to extract all the value, or they could fine tune the models to work best on their own developer tooling.
But right now, it would be profoundly arrogant to assume that any company has a lock on any part of the dev tooling space, or even to say with confidence what the dev tool space will look like in a few months/years. Lower barriers to entry mean an increase in diversity. It is far more likely that the market will fragment based on taste and aesthetic and minor feature convenience, things that are important to small market segments that the big labs simply can’t justify tackling. Let a million flowers bloom, as the saying goes.
Does this mean that everyone will simply build their own tools? After all, that is the best way to get maximum configurability. Where are the software moats?
If you ask me, the build vs buy line has changed, but it hasn’t changed that much. The majority of programmers are still people working unsexy desk job 9-5s at your major bank chain of choice. These people are not going to invest a ton in building their own AI dev tools, any more than they were likely to build their own IDE or Kanban board. Right now, there is no clear idea of what AI dev tools will look like or who the big trusted players are. CTOs and eng teams will fill that gap, because the gap needs to be filled. But when good, convenient, easy to use alternatives come along, I strongly suspect those same teams will offload their maintenance burden to other companies. A health tech CTO (for eg) probably doesn’t want to think about maintaining dev tools. Especially if those dev tools have a bunch of rough product edges that need to be rethought from first principles. The software moat is now very much a product moat. If your product feels good and is easy to use, it will still win out. And as I said before:
Every line of code is a liability, and there is always going to be demand for “you deal with this so I don’t have to.”
Last thought. You may notice that many companies appear several times in this article. As I said, ‘any team using agents effectively will run into these problems and concerns’. Teams that are using AI to build AI dev tools will naturally go out and build other parts of the dev tool landscape! That is 100% what we are doing at Nori. Looking forward a year, I suspect many AI dev tool companies will have suites of solutions, all of which will be considered table stakes for the AI dev tool category.
Agentics is the study of how to use and reason about agents. If you are an expert in coding agents, or interested in learning more about agents, join our community slack. More articles here.
If you are using coding agents and are thinking about building your own remote sessions infrastructure, check out norisessions.com and reach out instead!
You May Also Like:


trying desperately to not get into a long tangent about Aristotelian telos
larger enterprises are certainly just doing this in house
probably Composio?
You could point to a company like Perplexity as a sorta-kinda an exception, except it too also trains models
This is partially why side effects can be really dangerous for LLMs to deal with. Side effects do not have direct links between cause and effect expressed in a stack trace, which makes them very difficult for LLMs to reason about.
it is crazy to me that localstack is open source
it isn’t really a dev tool and isn’t really a viable “build it myself” consideration for most people
bookmarked, need to revisit this when I have more time to dig in