
Agentics: Your agent skills are all slop
We believe in only the finest, hand crafted, barrel aged, artisanal skills

Agentics is a series of posts about how to use and reason about coding agents. If you are an expert in coding agents, or interested in learning more join our community slack. More articles here.
As of this writing, there are nearly 100k code references to SKILL.md on github.
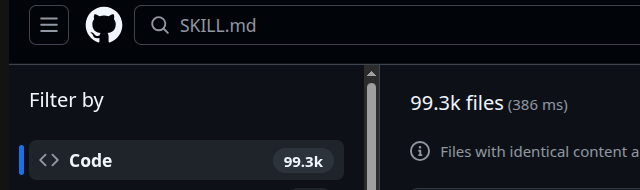
This is extremely early in the market penetration for skills overall. Skills were announced by Anthropic almost exactly 3 months ago, and the Agent Skill standard only went live last month. Most developers have not used any coding agents, much less understood the minutiae of skills, subagents, agents.md, etc. etc. So even though there are already ~100k code references to skills, I expect this number to increase dramatically.
What is an Agent Skill? It’s a markdown file with some instructions for the agent. You can think of it like a persistent extended prompt that lives on your computer, that the agent can call on whenever it needs. The implementation is extremely simple, which in turn makes it very flexible. You can use skills to do everything from storing pre-defined workflows to providing instructions on how to use third-party tools and APIs.
The SKILL.md file is rapidly replacing MCP as the de-facto integration standard for coding agents. Claude Code uses it, of course. Codex recently announced support. Gemini and Cursor support is still in experimental mode, but the writing is on the wall there. It’s easy to see why. SKILLs are readable, easy to understand, easy to transport / copy / modify. You don’t have to understand anything about clients and servers and specs. It’s just a file. Agents read files all the time, so there’s nothing weird about reading SKILL files in particular. In fact, Agents are often better at using skills than they are at calling MCP servers!1
Despite the obvious importance of skills, there is as of yet no standardized way to discover skills. For example, if you search for ‘creating-skills/SKILL.md’, you will find 76 different versions of a skill for creating skills.

No idea which one of these is the best, or even good.
To try and find good skills, people have taken to producing massive lists of dozens of otherwise-unrelated skills on github. It’s giving very Web 0.1. The problem, of course, is that you also can’t find those lists! There are 53 different repositories called ‘awesome claude skills’!
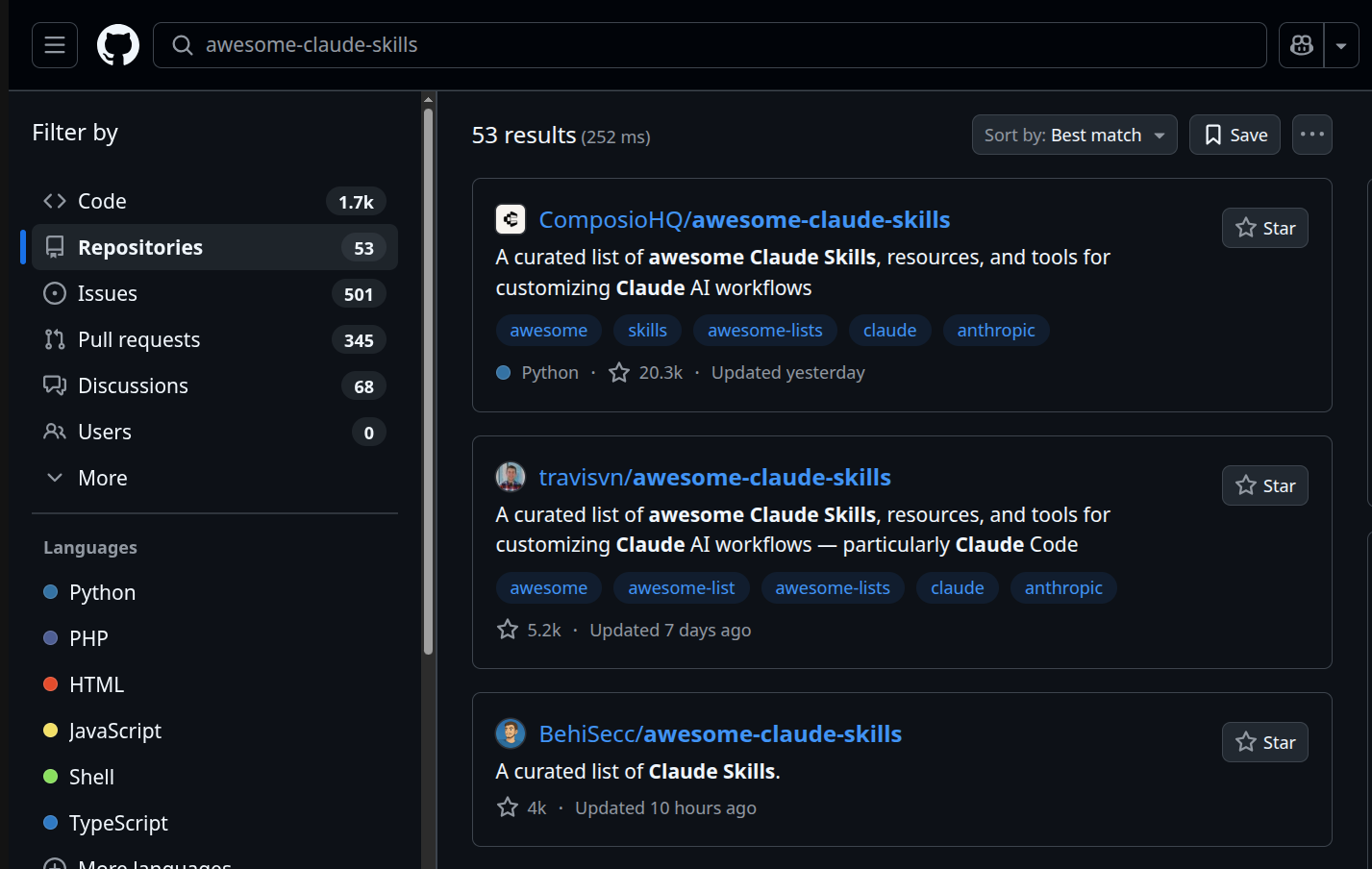
This is, bluntly, a massive sea of shit. Most of these skills are bad. A huge huge chunk of them are written by AI without any guidance. These are possibly the worst, because AI tools do not yet know how to write good skills.2
I’m going to make fun of Letta a bit. Letta.ai is an AI platform for making LLMs better. They have built some really impressive tools around giving LLMs long term memory, and I’ve been super impressed with their research overall. But can they write skills? They have a ‘creating-skills’ skill in their public repo that you can find here. The first ‘Core Principle’ in this skill is the following:
### Concise is Key
The context window is a public good. Skills share the context window with everything else the Letta Code agent needs: system prompt, conversation history, other Skills’ metadata, and the actual user request.
**Default assumption: the Letta Code agent is already very capable.** Only add context the Letta Code agent doesn’t already have. Challenge each piece of information: “Does the Letta Code agent really need this explanation?” and “Does this paragraph justify its token cost?”
Prefer concise examples over verbose explanations.This skill uses 3870 tokens! It is not concise. It is definitely not treating the context window as a public good. Claude Code starts going to shit after ~100k tokens, so you’re using ~4% of your effective context window on just this one skill.
But maybe it is just that one skill? Maybe ‘creating skills’ as a concept is fraught and it is worth spending those tokens? Maybe. But other Letta skills are also very large — initializing-memory is 3766 tokens, defragmenting-memory is 1436 tokens, and Letta’s smallest skill, finding-agents, is still 875 tokens.
As a point of comparison, over at nori, we also have a ‘creating-skills’ skill. It’s 530 tokens.
To be clear, Letta’s skills are in the top 99% of all skills that are out there. Despite my criticisms (of which token count is a small fraction), they are really much better than most. And Letta is just following Anthropic’s lead — the Anthropic skill-creator skill, is itself 3673 tokens.3 But I think that speaks to how hard it is to find good skills, or even people who can be trusted to write good skills.
In order to plug the gap, a few skills-indices have cropped up, e.g. skillsmp. Unfortunately, they rarely are better than just using Github Search directly. The skillsmp site boasts 66k skills. Which ones are good?

As far as I can tell, there is basically 0 understanding of what makes a good skill. So what proliferates in the market is slop, and search indices for that slop. It happens to me all the time. I will see a skill that I think is cool, try it out, and realize that it doesn’t work. Or that it actively makes my agent worse. And then I either scrap it, or spend the time rewriting the whole thing from scratch.
At Nori, we’ve developed a very opinionated skills template.
Every skill must be less than 150 lines. Ideally less than 100.
Skill “descriptions” are not actually descriptions. The description should explain to the agent when to use the skill. They should not summarize the skill, unless that is useful to explain when to use the skill (it often is not useful).
Most skills are “processes” that follow a strict set of step by step instructions. These must have a <required></required> block at the top, with explicit instructions to use the agent TodoList tool. Here’s an example from our test-driven-development skill.
<required>
*CRITICAL* Add the following steps to your Todo list using TodoWrite:
1. Write a failing test (RED phase)
2. Verify the test fails due to the behavior of the application, and NOT due to the test.
<system-reminder>If you have more than one test that you need to write, you should write all of them before moving to the GREEN phase.</system-reminder>
3. Write the minimal amount of code necessary to make the test pass (GREEN phase)
4. Verify the test now passes due to the behavior of the application.
- If you go through three loops without making progress, switch to running `{{skills_dir}}/creating-debug-tests-and-iterating`
5. Refactor the code to clean it up.
6. Verify tests still pass.
</required>Skills that are just integrations to a CLI tool or script are rare. They should be very thin. Let the cli tool do most of the talking, eg by having good error messages when the agent does the wrong thing or provides the wrong input.
All skills need to be referenced in the Claude or Agents.md explicitly, with their full file path and their description.
Use fake XML tags. Note that Claude Code has <system-reminder>, <good-example>, and <bad-example> in its system prompt; it may be fine tuned on these specifically.
Use first person. “Ask me to do ABC” instead of “Ask the user to do ABC.”
I could go on.
All of these guidelines come from constantly tweaking skills to get the model to behave. There’s hours of work in there, but importantly, it’s work that is totally different from regular software. Just because someone is good at writing code does not mean that they can write skills. Every single skill in the nori-skillsets repo is essentially handcrafted (artisanal, barrel aged) over dozens if not hundreds of iterations.
Right now, there is a massive trust gap. Normally, if Vercel puts out some software, I can generally trust that the software is good, because it’s from Vercel. But we’re in a brave new world. Are Vercel’s skills any good? Do the folks at Vercel actually know how to write them?4 Curation and taste matter. There is a need for an AI npm or pypi, a package manager that is an ecosystem backbone, one that does a good job surfacing the best tools instead of simply indexing all of them without care for quality. We’re working on solving this problem in our corner of the world with nori-skillsets, but only because I think the big players have dropped the ball and left a big gap to fill.
Agents have a lot of ‘experience’ reading files and using CLI tools. By comparison, they have no experience using MCP. MCP is a recent invention, so information about how to properly use MCP has not made it into training datasets en masse.
Models can’t write good skills because skills have also not hit the training datasets yet.
Note that there’s enough overlap between the Anthropic and Letta versions of this skill that Letta likely forked Anthropic’s implementation. Which is not at all a ding on Letta! That just speaks to how fragmented this part of the ecosystem is, that folks are literally just copy pasting files instead of any kind of version tracking or history.
Actually, yes, I think the skills here are very high quality. But they are also very very specific, which makes them less useful for the average developer. And I’m very suspicious of the 16k token react-best-practices/AGENTS.md file.
This resonates hard. From a physician-scientist perspective, what you’re describing is the classic “unregulated supplement market” problem, except the substrate is context budget and the adverse effect is cognitive impairment of the agent (hallucination, goal drift, brittle behavior) rather than liver enzymes.
A few parallels that feel useful:
1. Skills need a dosage form + labeling. Token count is dose, and right now we’re handing people 4,000-token “capsules” that claim to be “concise” while quietly consuming a meaningful fraction of effective context. Your <150-line rule reads like a safety standard. 
2. We’re missing the equivalent of pharmacovigilance. The market is optimizing for “exists on GitHub” not “improves outcomes.” What we need is post-market surveillance: regression tests for agent behavior, A/B evals, and public “side effect” reporting (when a skill reliably increases error rate). 
3. Curation beats indexing. A package manager that surfaces trustworthy skills (with benchmarks, failure modes, and versioning) is basically an FDA + formulary + Cochrane combo for agent workflows and your point about the trust gap is spot on. 
Love the “description = when to use” reframing, and the emphasis on thin integrations where the tool does the talking.
"There is a need for an AI ... package manager that is an ecosystem backbone, one that does a good job surfacing the best tools instead of simply indexing all of them without care for quality. ...the big players have dropped the ball and left a big gap to fill."
100 percent. Thanks for articulating this problem and resultant frustration so clearly, AND a first crack at mitigation that's worth exploring.